Data Quality: The First Frontier for Enterprise AI Adoption
September 23, 2025

Pramit Rajkrishna
Director Solution Consulting
Pramit is the Director of Digital Strategy for Sitation, specializing in product data management and governance, PIM implementations and site, organic and paid search and currently oversees consulting and PIM implementation engagements with Sitation’s enterprise and mid-market customers. Prior to joining Sitation in 2019, Pramit was the Data Strategy and Operations Manager for the Digital division of Arrow Electronics (Fortune 102), based in Denver, CO from 2015 to 2019, driving the reimagining of a new digital experience for the company’s core electronics components distribution business.
Pramit has a Masters in Electrical Engineering from Colorado State University and is certified in Riversand and Salsify PIM platforms, in addition to being certified in Lean-Agile and a Certified Scrum Product Owner (CSPO) by Scrum Alliance.

This is Part 2 of a 5-part series where we will take a deeper look at the fundamentals of organization-wide AI platform deployment and adoption.
In Part 1 of this series, we covered the five core aspects of AI adoption in the organization for delivering value:
- Data Quality
- AI Algorithms
- Data Integration
- AI Workflows
- Change Management
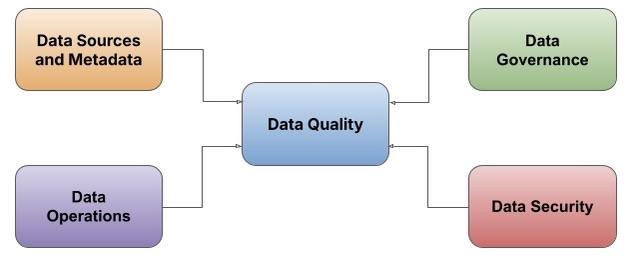
In Part 2, we will cover the first aspect and the key role of data quality as a primary step and prerequisite for effective AI adoption within the organization. Data quality arguably is the most important aspect of an AI-enabled organization, given the outsized impact on the quality of outputs from the AI models – and the resulting business value. The key foundational elements of data quality for effective AI implementations are four-fold:
- Data Sources and Metadata – Choosing the right data sources across the organization and data points to run the AI model.
- Data Operations – Performingdata sanitization operations on the data sources prior to model ingestion.
- Data Governance – Configuring business rules for data transformation prior to ingestion into the data model.
- Data Security – Ensuring data partitioning and provisioning robust access controls on source and target data to preserve data security standards.
Data Sources and Metadata
As a first step for a private AI model deployment in the organization, it is important to establish the key data sources to train the identified AI algorithms. These data sources could contain operational, marketing, sales, customer, and product data from across the organization, which will need to be configured for ingestion to the AI models. The identified data sources need to be profiled for any pre-ingestion operations to ensure clean training data intake to the AI models.
An supplemental activity, as part of identification of the data sources, is to select the correct data points among the data sources to configure the AI models. The metadata is the driving factor for the algorithms in the AI models and is imperative to profile in terms of coverage, sanity and more importantly availability to ensure the analysis is run on the pertinent data points to generate relevant output.
Data Operations
The next step is identification of data sanitization operations such as ranking, normalization, survivorship, cleansing and enrichment among others. These operations ensure that source data is correctly profiled and configured prior to ingestion into the AI models. A brief overview of the core operations are:
- Ranking – Metadata ranking is key to informing the AI models to pick the correct input in order of priority from each data source
- Normalization – Normalization is required if multiple data sources have redundant data and they have to be cleaned to avoid duplication
- Survivorship – Survivorship determines the data point to be used for a model if multiple data sources have the same data point
- Cleansing – This is an intensive exercise if certain data sources have inconsistent data and formats and standardization is required in order to feed data to the AI models
- Enrichment – This exercise is required if data sources are missing coverage on key data points and would result in poor output from the AI models.
Data Governance
A subsequent step prior to data transmission to the AI models is to define the business rules and transformations on the data points from the data sources. This operation is typically performed in the integration layer as a penultimate step before the data being loaded into the AI layer.
A key step in this process is ensuring that business rules are configured in tandem with the data sanitization operations to correctly convert the data as per business needs, prior to processing by the AI models.
This topic will be covered in more detail in the next blog on data integration.
Data Security
Data security is a fundamental aspect as data quality because, while it does not influence the material quality of data, it ensures that access to input and output data from the data is access restricted by user roles and is also tied to the data governance layer to ensure the correct user set is able to access their respective provisioned data.
The AI data security infrastructure is defined by integration with the organization’s current commercial authentication mechanisms, in addition to access controls by user groups on the data sources and targets from the AI models. Furthermore, access permissions to the configuration and execution of the AI models and associated tools is another layer that needs to be considered as part of the data security architecture.
In summary, these four aspects serve as the core foundation for data quality in the AI enabled organization and are necessary pre-requisites for deploying a successful AI implementation. In the next blog, we will cover data integration as a key factor in importing data into the AI models and exporting data from the models to various organization endpoints.
If your organization is preparing for AI adoption, ensuring strong data quality is the essential first step. Connect with us to learn how Sitation can help you build a trusted data foundation for AI success.
