Scorecards: Evaluating Content at Scale with Artificial Intelligence
February 29, 2024

A good system we use for evaluation of whether or not a task is a good candidate for automation via AI is if that task requires a “stop, onboard, and act” moment. Does this task make you stop, onboard some information into your brain, and then take an action while you are holding that information in your memory? If so, AI might be able to help.
Take the act of writing a product description. This is a task that requires focus; a person needs to stop what they are doing and focus fully on creating a product description. Next, they need to load contextual information into their brain. What product is this, what are the features? What audience am I writing for? What formatting do I need to take into account?
Finally, they need to act and write the product description according to everything they know about the product and the task at hand at the time.
Content generation is the classic example of this, and something LLMs (large language models) are particularly well-suited for. However, there is another task that requires a similar pattern of human-led focus that can be automated by AI, and that’s interpreting existing content and evaluating it.
We’ve created a feature in RoughDraftPro that allows you to do this – it’s called Scorecard.
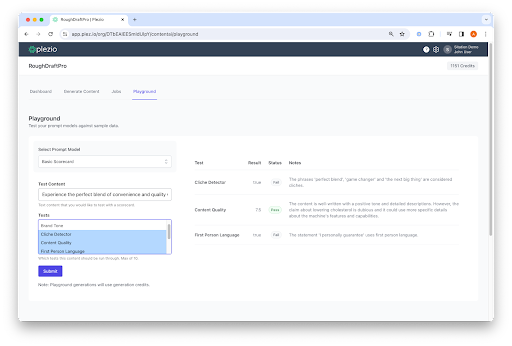
Scorecard
The power of Scorecard is the ability to not just ask AI simple, direct questions about content, but to ask the types of questions that follow the “stop, onboard, and act” pattern outlined above. These can be complex, qualitative questions that leverage the power of AI to understand and interpret language.
For example, you can ask AI to evaluate a piece of content based on how well it adheres to a stated set of brand guidelines, whether it contains cliches, or even if it’s just generally compelling content. These are all genuinely useful evaluations that go beyond basic text analysis.
A Test Framework
While it’s relatively straightforward to ask ChatGPT or other LLMs to evaluate pieces of content individually, RoughDraftPro’s Scorecard system is designed to let users evaluate content in bulk, as well as interpret those results. Scorecards can be run just like RoughDraftPro prompts: either individually in the prompt playground, or in bulk within a content generation flow. Each scorecard prompt can run multiple tests in one generation, and all results are reported individually in separate data columns for easy use in other systems.
Flexible Score Types
Many tests in scorecard work on a true/false result: either content meets certain criteria or it doesn’t. For more subjective evaluations, we can build Scorecard tests that allow AI to return a score from 1-10. This allows you to quickly rank content in bulk based on subjective tests.
Evaluation Beyond AI’s Output
Scorecard is able to set a pass or fail status on AI’s evaluation of content, meaning that Scorecard will interpret the results of the AI output and assign them a pass/fail status based on that specific test’s criteria.
For example, if your Scorecard test is scoring content based on adherence to brand voice, you may only consider scores above 6 to be a passing grade. Scorecard will evaluate this output and assign pass or fail based on the score from AI. This system will also evaluate true or false evaluations based on which value the test considers passing.
Combining AI with Basic Logic
Scorecard also has the ability to compile AI logic with what we call “basic logic,” or tests that classic programming logic would be better suited to handle.
For example, you might want to run a test for if content adheres to a specific brand tone alongside an assertion that the character count of the content does not exceed 255 characters, or that it contains a certain set of keywords. These are tests that are not well-suited to large language models, and we might not always get the correct answer. Basic logic allows us to make Scorecards reliable and useful.
Running Evaluations at Scale
Like anything that RoughDraftPro does, scorecards can be run in bulk, meaning that large sets of content can be evaluated by AI in the same way that we generate content with RoughDraftPro.
If you have the need to evaluate and score content, contact us for a demo of RoughDraftPro’s Scorecard functionality.
